The
distribution of values within an index will often affect
the cost-based optimizer (CBO) decision whether to use
an index or perform a full-table scan to satisfy a
query. This can happen whenever the column referenced
within a SQL query WHERE clause has a non-uniform
distribution of values, making a full-table scan faster
than index access.
Column histograms should be created only when you
have highly-skewed values in a column. This rarely
occurs, and a common mistake that a DBA can make is the
unnecessary collection of histograms in the statistics.
Histograms tell the CBO when a column's values aren't
distributed evenly, and the CBO will then use the
literal value in the query's WHERE clause and compare it
to the histogram statistics buckets.
If your SQL workload uses bind variables for all SQL (a
best-practices approach), then you should nuke your histograms and disable
histogram creation in the future (via method_opt).
Using histograms to improve table join order
Histograms can help the cost-based optimizer estimate the
number of rows returned from a table join (called "cardinality") and histograms
can help. For example, assume that we have a five-way table join whose
result set will be only 10 rows. Oracle will want to join the tables together in
such a way as to make the result set cardinality of the first join as small as
possible.
By carrying less baggage in the intermediate result sets, the
query will run faster. To minimize intermediate results, the optimizer attempts
to estimate the cardinality of each result set during the parse phase of SQL
execution. Having histograms on skewed column will greatly aid the optimizer in
making a proper decision. (Remember, you can create a histogram even if the
column does not have an index and does not participate as a join key.)
Oracle 10g has also introduced
dynamic sampling to improve the CBO's estimates of inter-table row join
results.
Even with the best schema statistics, it can be
impossible to predict a priori the optimal table-join
order (the one that has the smallest
intermediate baggage). Reducing the size of the
intermediate row-sets can greatly improve the
speed of the query.
In this example, the four-way table join only
returns 18 rows, but the query carries 9,000
rows in intermediate result sets, slowing-down
the SQL execution speed:
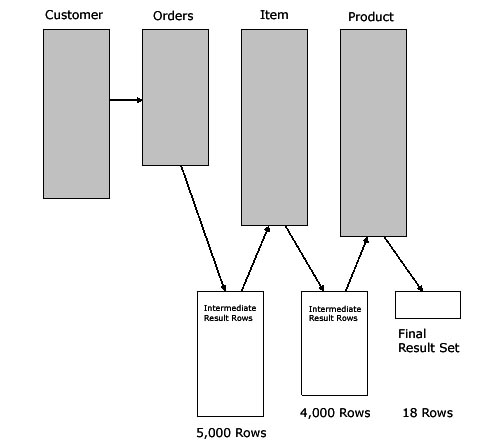
Sub-optimal intermediate row sets.
If we were somehow able to predict the sizes of
the intermediate results, we can re-sequence the
table-join order to carry less intermediate
baggage during the four-way table join, in this
example carrying only 3,000 intermediate rows
between the table joins:
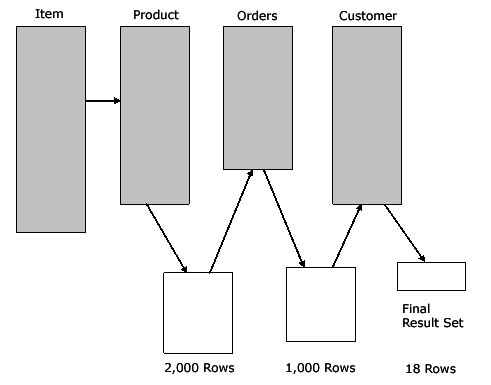
Optimal intermediate row sets.
Finding "missing" table join
predicates (too add histograms)
Oracle expert and author John Kanagaraj
has an very sophisticated
query to detect columns that are used as table join
predicates:
You should be able to use SYS.COL_USAGE$ to work out which
columns are being used in Join predicates using the following SQL:
select
r.name owner,
o.name table ,
c.name column,
equality_preds,
equijoin_preds,
nonequijoin_preds,
range_preds,
like_preds,
null_preds,
timestamp
from
sys.col_usage$ u,
sys.obj$ o,
sys.col$ c,
sys.user$ r
where
o.obj# = u.obj#
and c.obj# = u.obj#
and c.col# = u.intcol#
and o.owner# = r.user#
and (u.equijoin_preds > 0
or u.nonequijoin_preds > 0);
A MINUS against DBA_IND_COLUMNS should show up which columns *might* need
Histograms....
In a blog titled "Histograms
for table join predicates"
the author explains the
problem and how to use histograms as a
solution. The thrust of the argument
is that histograms will help detect "skew"
in table join columns when using
synthetic keys (STATE#). Aldridge
shares his conclusions and solutions to
sub-optimal table join order:
- Partition or subpartition the fact table on
STATE#. (preferred option)
- Create a summary table with partitioning or
subpartitoning on STATE#. (uses most space and slows
data load, but very flexible and powerful)
- Create a function-based index on fact to perform
the lookup, and query that value instead. (a bit
flaky, but it works without major system impact)
- Rebuild the fact table based on the STATE_NAME
instead. (still limited in multi-level hierarchies)
A new feature of the dbms_stats package is the
ability to look for columns that should have histograms,
and then automatically create the histograms. Oracle
introduced some new method_opt parameter options
for the dbms_stats package. These new options are
auto, repeat and skewonly and are
coded as follows:
method_opt=>'for all columns size auto'
method_opt=>'for all columns size repeat'
method_opt=>'for all columns size skewonly'
Automatic histogram generation
The auto option is used only when monitoring has
been invoked via the alter tablemonitoring
command. Histograms are created based upon both the data
distribution (see Figure A) and the workload on the
column as determined by monitoring, like this.
execute dbms_stats.gather_schema_stats(
ownname => 'SCOTT',
estimate_percent => DBMS_STATS.AUTO_SAMPLE_SIZE,
method_opt => 'for all columns size auto',
degree => DBMS_STATS.DEFAULT_DEGREE);
 Evenly distributed data vs. skewed
data distribution
Evenly distributed data vs. skewed
data distribution
Using the dbms_stats repeat option, histograms are collected
only on the columns that already have histograms.
Histograms are static, like any other CBO statistic, and
need to be refreshed when column value distributions
change. The repeat option would be used when
refreshing statistics, as in this example:
execute dbms_stats.gather_schema_stats(
ownname => 'SCOTT',
estimate_percent => DBMS_STATS.AUTO_SAMPLE_SIZE,
method_opt => 'for all columns size
repeat',
degree => DBMS_STATS.DEFAULT_DEGREE);
The skewonly option introduces a very
time-consuming build process because it examines the
data distribution of values for every column within
every index. When the dbms_stats package finds an
index whose column values are distributed unevenly, it
creates histograms to help the CBO make a table access
decision (i.e., index versus a full-table scan). From
the earlier vehicle_type example, if an index has
one column value (e.g., CAR) that exists in 65 percent
of the rows, a full-table scan will be faster than an
index scan to access those rows, as in this example:
execute dbms_stats.gather_schema_stats(
ownname => 'SCOTT',
estimate_percent => DBMS_STATS.AUTO_SAMPLE_SIZE,
method_opt => 'for all columns size
skewonly',
degree => DBMS_STATS.DEFAULT_DEGREE);
Tools to assist in CBO histogram tuning
There are many tools to assist with SQL
tuning, but the best tools will expose all of the
internal metrics of the data dictionary. The Ion
tool does a great job at aiding SQL
tuning:

Ion screen for SQL tuning
The Ion
tool is an easy way to analyze Oracle SQL performance and Ion also allows you to
spot hidden SQL performance trends.
BC References on tuning with histograms
Also
see these related notes on cardinality estimation:
-
-
-
-
"Oracle
Tuning: The Definitive Reference", 2009, Donald K. Burleson, Rampant
TechPress
 |
|
Get the Complete
Oracle SQL Tuning Information
The landmark book
"Advanced Oracle
SQL Tuning The Definitive Reference" is
filled with valuable information on Oracle SQL Tuning.
This book includes scripts and tools to hypercharge Oracle 11g
performance and you can
buy it
for 30% off directly from the publisher.
|


